2月 4日 (土)
1. hn.org will be turning down by 2006.02.15
サービス停止ってマジですかー。急に言われても困るなあ。自宅のサーバを名前で引きたいときは結構あるので、とりあえずNo-IP.comでアカウントを取っておきました。
2. 吉里吉里
メッセージボックス表示関数を作成しました。MessageBoxのラッパーですけどね。
2月 12日 (日)
1. アキバ
アキバですよ、アキバ。某サイトでローカルに盛り上がっていたメイド喫茶漫画それ町とか、いい加減GigaEthernet環境への移行を始めようと思いまずはバックボーンからということでギガビット対応のL2スイッチとか、その他ごちゃごちゃと買ってきました。
本日の発見。トンカツ屋の和幸で千円以下のメニューが復活していた(いつからだろう)。しかも禁煙だった(いつからだろう)。素敵だよ、和幸。
2. ギガ
スイッチだけをギガビットにしても全体の通信速度は全く変わりませんが、とりあえず交換しておきました。次は「蟹」をどうにかしたいですね。五年弱の間、一度も止まらずに働き続けてきた100BASE-TのL2スイッチは引退です。引退とはいってもまだまだ普通に使えるので、大切に保管しておきましょう。
2月 13日 (月)
1. 吉里吉里
プラグインがいつまで経ってもβ版な件について。
次はポップアップメニューを実装したいなー、と考えてます。Windowsアプリケーションでありがちな、所謂「右クリックメニュー」ってやつです。今まで吉里吉里2にはありそうでなかったんですよね、これ(私が知らないだけかも)。
…こんなことだからいつまで経ってもβなんだよ!
2月 16日 (木)
1. 吉里吉里
なんか出た。
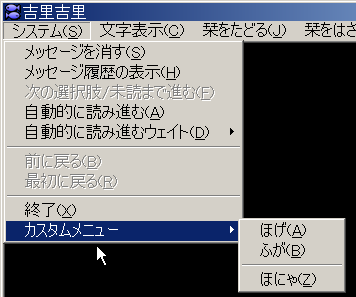

今のところ、おおよそ以下のようなコードを書くだけで、右クリックでポップアップできるようになってます。
//当然、メニュー作成は別途必要
//フック関数
function showPopup()
{
var x = kag.lastMouseDownX;
var y = kag.lastMouseDownY;
kag.trackPopupMenu(0, x, y, 0, 10);
return false;
}
kag.rightClickHook.add(showPopup);
が、あまり実用にはならないかもしれません。今わかっている欠点として、次のようなものがあります。
- 非表示状態のメニューはポップアップできない(当然か)
- 親メニューはポップアップできない(そういうものか?)
- 表示させるメニューは親メニューの子孫でなければならない
- 表示させるメニューの指定方法が、インデックスによる位置指定
始めの二つは諦めるとして、三つめはポップアップメニューの存在意義に関わります。親メニューの子孫に限定されるということは、ポップアップできるメニューは親メニューに登録されている、ということになります。親メニューにあるのであれば、ポップアップメニューにする意味はあるのか、と。
四つめは制作者に負担をかけるものです。インデックス指定ということは、制作者は常にメニューのインデックスを把握していなければなりません。吉里吉里のMenuItemインスタンスは、自身のインデックスを知る方法を持たないため、これは意外と厄介です。
三つめと四つめの妙な制限があるのは、MenuItemインスタンスからメニューハンドルを直接取得できないためです。直接取得できない以上、間接的にやるしかありません。現状では、ウィンドウハンドルからGetMenu()で親メニューハンドルを、親メニューハンドルとインデックスからGetSubMenu()で子メニューハンドルを、…といった感じに孫、曾孫、と辿っています。また、MenuItemからは事実上有益な情報を何も取得できないため、MenuItemコンテキストで実行することに何のメリットもありません。メニューなのにWindowインスタンスのメソッドになっているのは、このためです。
MenuItemインスタンスから、ネイティブインスタンスを無理矢理引きずり出してやろう *1 かとも考えましたが、ネイティブインスタンスのクラスIDやら、ネイティブインスタンスのクラス定義やら、VCLヘッダやら、いろいろと面倒なことになりそうだったのでやめました。
要するに、いま一つ使いづらい仕様になったということですが、どうしてもポップアップメニューにしたいというときには使えなくもないです。
- *1: ネイティブインスタンスはVCLのTMenuItemオブジェクトを保持(has a)している。TMenuItem::Handleでハンドルを取得できる。
2月 25日 (土)
1. 地獄少女対地獄少年
今回の地獄少女は、ローゼンメイデンのような少女です。これはスタッフの趣味でしょうか。こんばんは。
地獄少女ってとりわけ面白いわけではないのですが、時代劇みたいに毎回展開がワンパターンなので、安心して見られます。ぼーっと見るには向いてますね。
あー、ローゼンメイデンは見たことないです。
2月 26日 (日)
1. ISBN DB
国内外を問わず、普通に出版社から出版された書籍にはISBNが付きます。ただし、雑誌やムックには付きません。海外は知りませんが、日本の雑誌には別に雑誌番号が付きます。当然、同人誌(同人雑誌)には付きません。正規のルートを通ってませんしね。
ISBNが決まると、一意に書籍が決まるので、出版地域、出版社、書名、を特定できます。そこまで決まれば、著者や出版年なども容易に導くことができます。ただし、版や刷りまではわかりません。そういった情報は含まれていないからです。
さて、以前からISBN周りのデータベースが欲しいと思っていました。ISBNとその周辺情報を何とか手に入れられないかと考えたのですが、この辺は「ビジネス」として成立しているらしく、ただでは手に入りません。定期更新も含めて年間契約でン百万らしいです。とてもじゃないですが、そんな金払えません。
ないものは作ってしまえ、ということで、作ります。もちろん手入力で…なんて面倒なことはしません。完全で体系的、とは言えませんが、WWWにはそれなりに豊富な情報があります。例えば、本屋のウェブサイトとかね。適当にウェブクローラー(ロボット)を作って、これらのサイトを適当に徘徊させながらISBNとその付随情報を集めてくれば良いでしょう。自動収集させるので、
- ISBNからURLを容易に作成できる
- 他の関連した書籍情報を同時に取得できる
- 情報が豊富
- ページから情報を取得しやすい
- JavaScript不要
- Cookie不要
が必須条件となります。これらの条件に適合したサイトを探すのは容易ではありません。まずはサイト探しです。
楽天はページの汚さはamazon級 *1 ですが、関連書籍の情報量が少ないため、とりあえず候補から外します。JavaScriptが有効でないと閲覧すらできない丸善は論外、Cookieが有効でないと一部のページにアクセスできないJBOOKも候補から外します。ほか、ISBNからURLを作成しにくいサイトも対象外です。
残ったのはamazonとManaHouseです。amazonの吐くページには、その書籍以外にも関連した書籍情報がありますから、関連書籍情報の豊富さではamazonが有力です。ただし、ページから書籍情報(書籍名や著者名など)を取り出すには、ManaHouseの方がやりやすそうです。ManaHouseにない書籍は、仕方がないのでamazonから取得します。
次にクローラー(ロボット)の方ですが、実装するのが面倒なので、wgetにします。機能的にも豊富ですし、WindowsでもLinuxでも使えます。
取得したデータはRDBに保存します。RDBMSにはSQLiteを使用します。
- DBファイルのバイトオーダーを気にしなくて良い(プラットフォーム間移植性)
- 多くの言語にバインディングがある(言語間移植性)
- DBファイル一つでバックアップ〜リストア可能(保守性)
- UTF-8/16対応(書籍名を扱うなら当然Unicode)
- せっかくisqliteを改造したので使ってみたい(趣味)
- SQLiteが好き(個人的嗜好)
といったところでSQLiteに決定です。
情報を取得する順序、つまり、次に何を取得すればよいかという情報は、「取得キュー」(FIFO)に保持します。キューはもう一つ、「解析キュー」というものもあります。キューにはISBNやURLを放り込んでいきます。 *2
キューの実装については二通り考えました。名前付きパイプとRDB上のテーブルです。名前付きパイプは、FIFOとも言われるファイルの一種で、ほとんどのUNIX系OSでは標準で実装されています *3 。多数のプロセスから同時に書き込める、読み出し順序が保証される、など、レギュラーファイルと異なる性質を持ちますが、扱い方はレギュラーファイルと大差ありません。多数のプロセスから同時に書き込みたいけど、ソケットやIPCを使うほどではない、といったときには結構便利です。しかし、Windowsにはありません。cygwin上でなら使えますが、cygwinの名前付きパイプは、大量のプロセスから一斉に書き込みまくると、プロセスが固まってしまうという欠点があります *4 。移植性や保守性、特にリストアに問題が出そうなので、名前付きパイプは使いづらそうです。
RDBテーブルにはそもそもキューの概念がありません。つまり、sequenceやserialの列を設けて、行の作成や取り出し・削除順序を自分で制御する必要があります。これらの列は、当然ユニークであり、かつNULLでないという制約下に置かれます。これはとりあえず主キーにしておけばよいでしょう。SQLiteでは、一意制約の実装としてユニークインデックスだけを利用している(?)っぽく、SQLiteの主キーはNULLを許可してしまいます。NULLデータの混入に気をつけた方が良さそうです。もっとも、INTEGER型の単一列主キーであれば、自動的にシーケンスを振ってくれる(PostgreSQLのSERIAL型に相当)し、NOT NULL(CHECK制約)にすれば回避できるし、あまり心配はないかも。
それよりも、エンキュー(挿入)、デキュー(削除)時に発生する、インデックスの再作成コストが心配です。前述の通り、キューは二つあります。WWWにアクセスして情報を取得するプロセス(ゲッター)は、この「取得キュー」から情報を読み、WWWからの情報を取得し、その結果(HTTPレスポンス本体)をファイルとして保存します。と同時に、その結果から関連書籍情報を取得し、今度取得すべきISBN,URLを「取得キュー」に登録します。さらに、「WWWから取得した」という情報は、「解析キュー」に書き込まれます。厳密な解析を行うプロセス(アナライザー)が別に稼働しており、このプロセスに解析を依頼するわけです。つまり、WWWから取得するたびに、「取得キュー」に対してデキューが一回、エンキューが0〜N回、「解析キュー」に対してエンキューが一回発生します。このコストは、キューにたくさん溜まっているときには意外と馬鹿にならないかもしれません。
次に、全体制御です。bashで済ませようかとも考えましたが、取得したページの解析など、強力な文字列処理機能が要求される局面では少々心許ないので、それなりのスクリプトが必要でしょう。
- 文字列処理が得意
- DBD-SQLiteでSQLiteを扱える
- Perlが好き
というわけでPerlに決定です。というか、それ以外は眼中にありません。 *5
制御する人(プロセス)は二種類あります。WWWからリソースを取得する人(ゲッター)と、リソースを解析する人(アナライザー)です。お互いに独立したプロセスなので、一人ずつ同時に存在するのはもちろん、多対一、多対零、零対多、…でもOKです。ゲッターは、WWWから一定間隔でリソースを取得する、デーモンとして稼働します。細かいことは前述の通りです。アナライザーは、適当な時間に「解析キュー」からデキューし、該当するリソースを解析して、解析結果(書籍名や著者など)を本体テーブルに登録します。この本体テーブルこそがISBN DBのコアです。うまく解析できなかったら、別のサイトからリソースを取得するよう、「取得キュー」にエンキューします。つまり「取得依頼」ですね。
こうして自律的かつ自動的にDBが出来上がっていく…はずなんですよ。実はまだ「ゲッター」しか実装されていなくて、取得することしかできず、キャッシュ(取得したリソースファイル)が溜まる一方です。アナライザーがないので、肝心の本体テーブルが構築されないわけで、ごにょごにょ。
- *1: amazonの吐くHTML(らしき文字列)を見たことのある人ならご存じでしょうが、それはもう酷いものです。よくもあそこまで汚く書けるものだと、ある意味感心します。解析する気も失せます。HTMLの文法を守る気が微塵ほどでもあるのかと問い詰めたいところですが、そもそもHTMLではありませんでした。http://www.amazon.co.jp/exec/obidos/ASIN/4839904545/ を HTML4.01 Transitional としてチェックしました。
- *2: wgetでごっそり再帰的に取って来ればいいじゃないかと思われがちですが、それでは能がないですし、余計なリソースまで取得される可能性が大きく、美しくありません。
- *3: lsコマンドでファイルタイプを見たときに、p と表示されます。レギュラーファイルは- 、ディレクトリはd ですね。
- *4: Perlで再現済み。Linuxではそんなことは起こりませんでした。
- *5: プロダクトが好き嫌いで決まっているような気もしますが、細かいことを気にしていては大物にはなれません。多分。
2月 27日 (月)
1. ISBN DB
昨日、書いてから気づいたのですが、「ゲッター」が関連書籍情報を取得するのはおかしいですね。一旦取得したリソースを解析するのはアナライザーの仕事ですから、関連書籍情報の取得と「取得キュー」へのエンキューも、アナライザーがやるべきです。ゲッターにはWWWからの取得に専念させた方が、設計として美しいです。
2. ゲームタイトルみたいな名前のキーボード
IBMのSpace Saver II(今はlenovoだっけ)というキーボードが欲しいのですが、新品では手に入らないっぽいですね。lenovoでは販売終了になっているようですし、アキバで中古品を探すしかないですかね。
2月 28日 (火)
1. βのままで 恥ずかしい
吉里吉里プラグイン。release版なのに、ドキュメントには堂々とβ版と書かれたままになっているあたり、さすがです、俺。そのままだと格好悪いので、こっそり差し替えておきます。